新一代多模态视觉语言大模型
星际大模型是世界杯官网基于10年AI视觉技术沉淀和10亿+真实业务数据集,推出的新一代多模态视觉语言大模型。
融合视觉感知与语言理解技术,兼具细粒度视觉感知与视觉理解的双重能力,仅需通过自然语言指令,即可精准定义目标物体和场景,并一键生成定制化的识别模型,实现超过80%视觉感知场景无需重新标注和训练,满足多场景下智能目标检测和定位需求,加速AI+业务应用和价值创造。


产品优势
 兼具"强性能"、"低幻觉、"可落地"三大优势,实现精准可靠的目标定位和智能分析,在复杂场景下保持稳定表现,支持快速部署与灵活扩展,全面支撑产业中多样化业务场景任务。
兼具"强性能"、"低幻觉、"可落地"三大优势,实现精准可靠的目标定位和智能分析,在复杂场景下保持稳定表现,支持快速部署与灵活扩展,全面支撑产业中多样化业务场景任务。

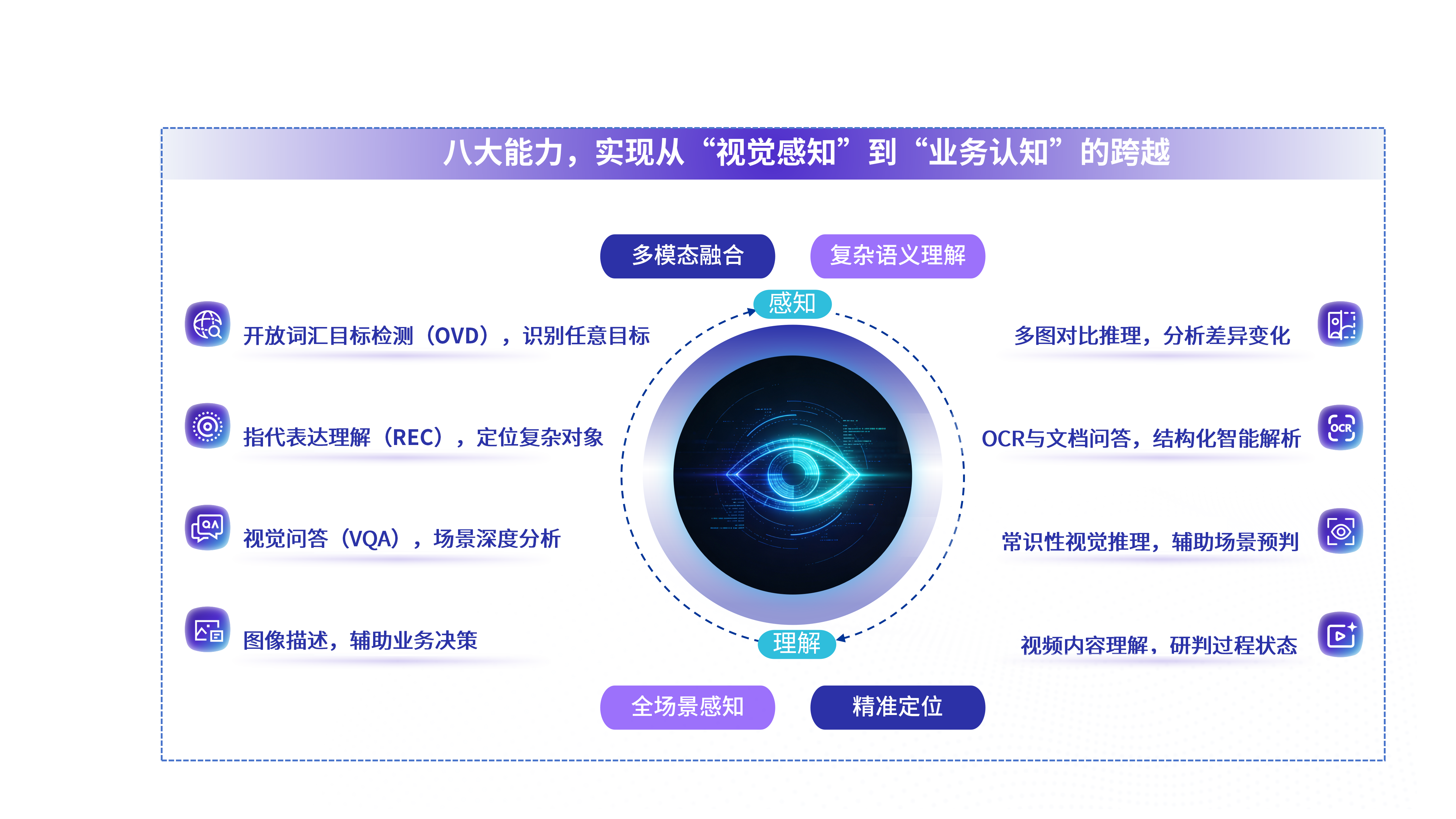
核心能力


开放词汇目标检测(OVD)
识别任意目标


指代表达理解(REC)
定位复杂对象


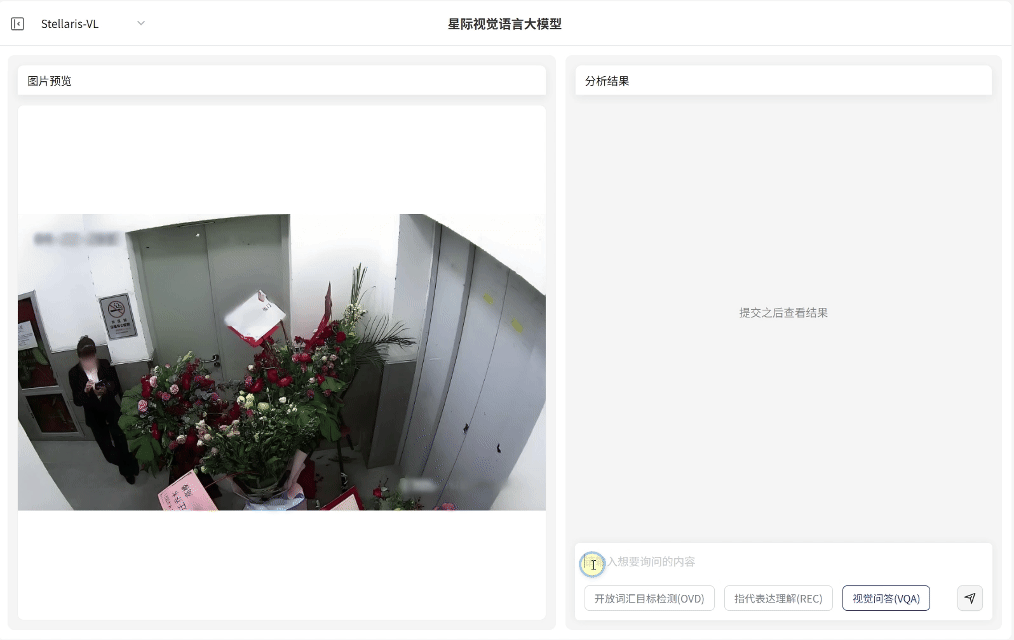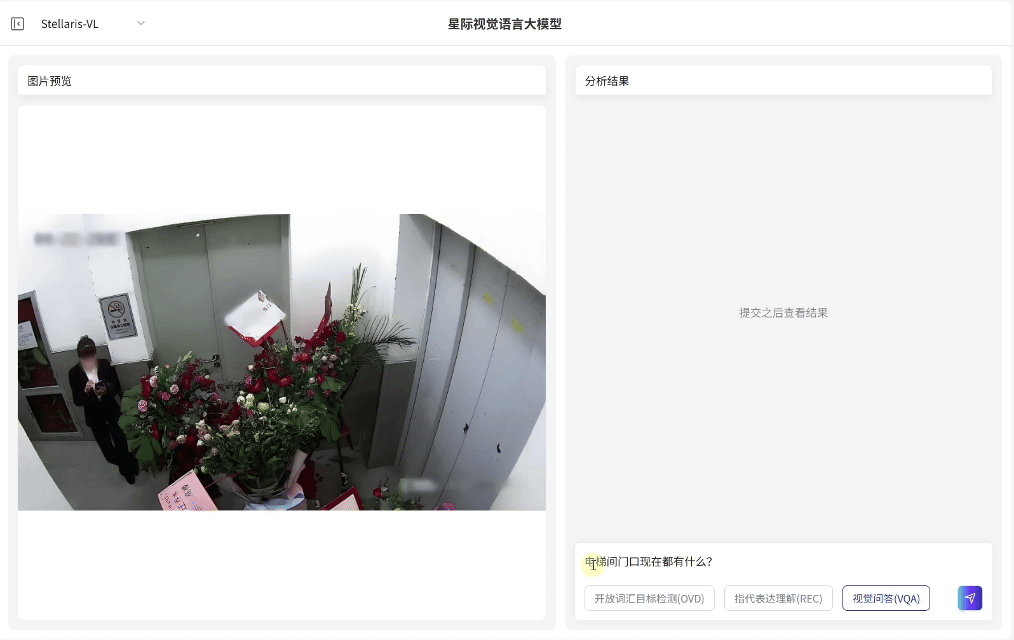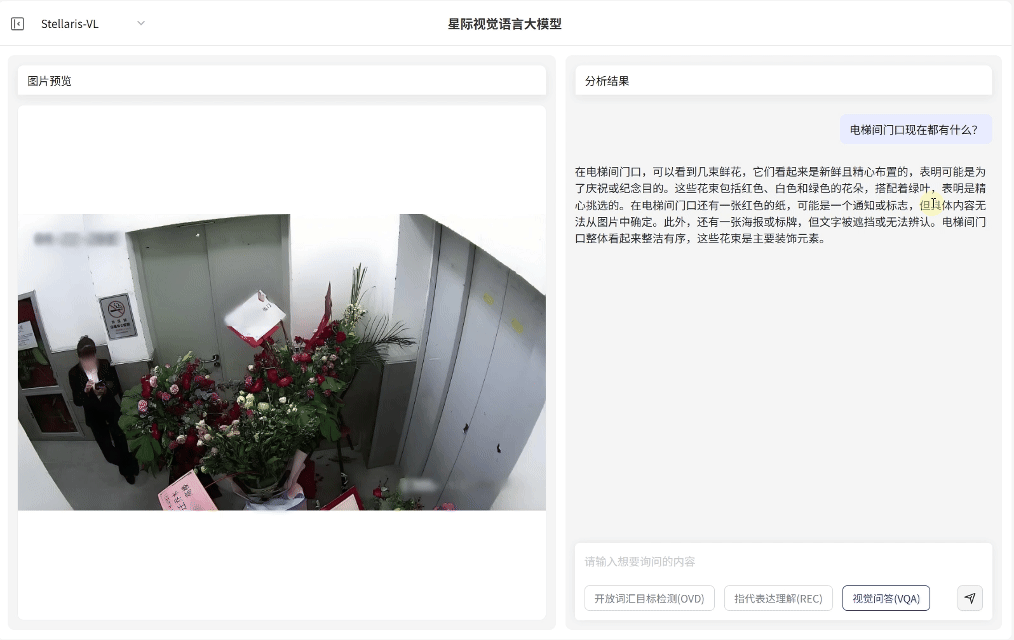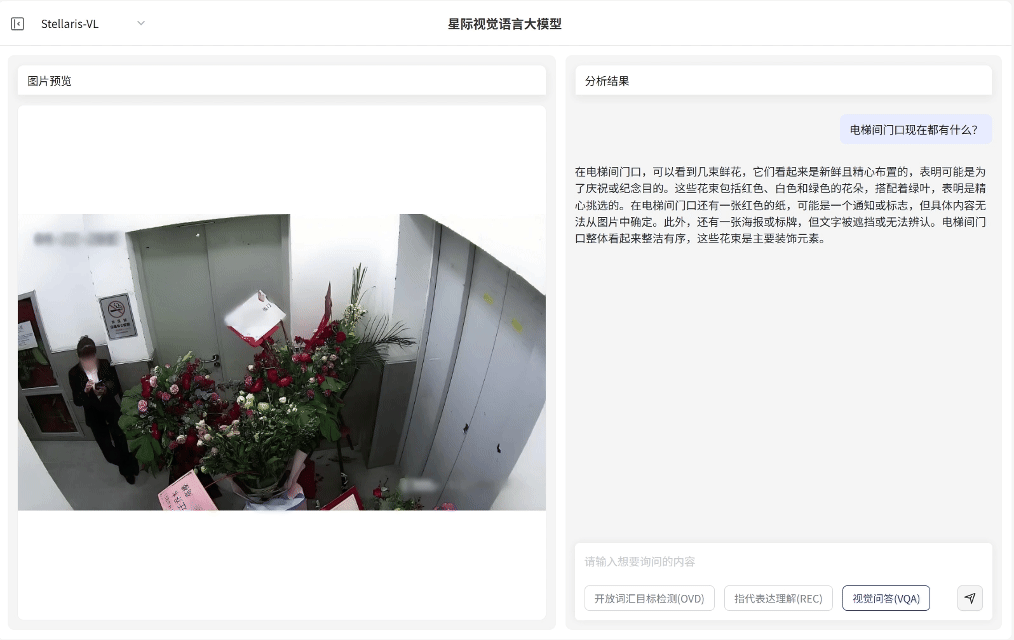
视觉问答(VQA)
场景深度分析


OCR 与文档问答
结构化智能解析


图像描述
辅助业务决策
开放词汇目标检测(OVD)
识别任意目标
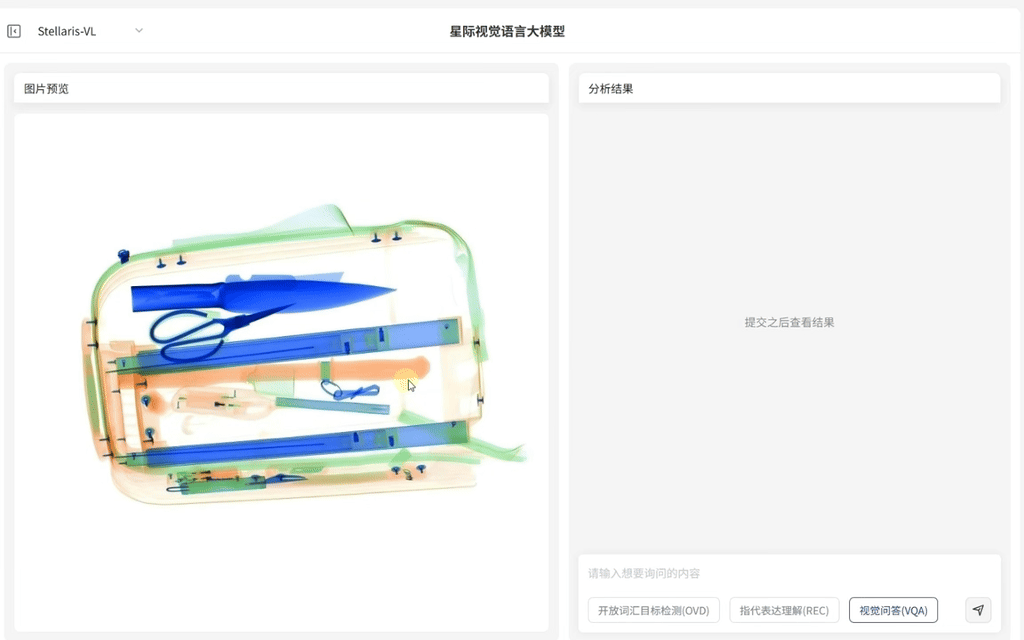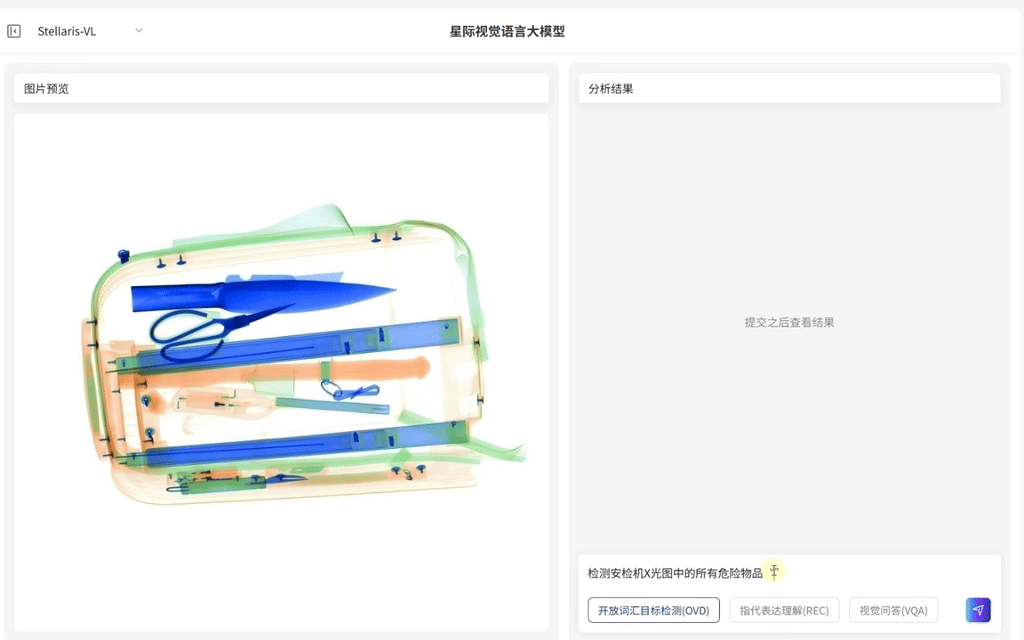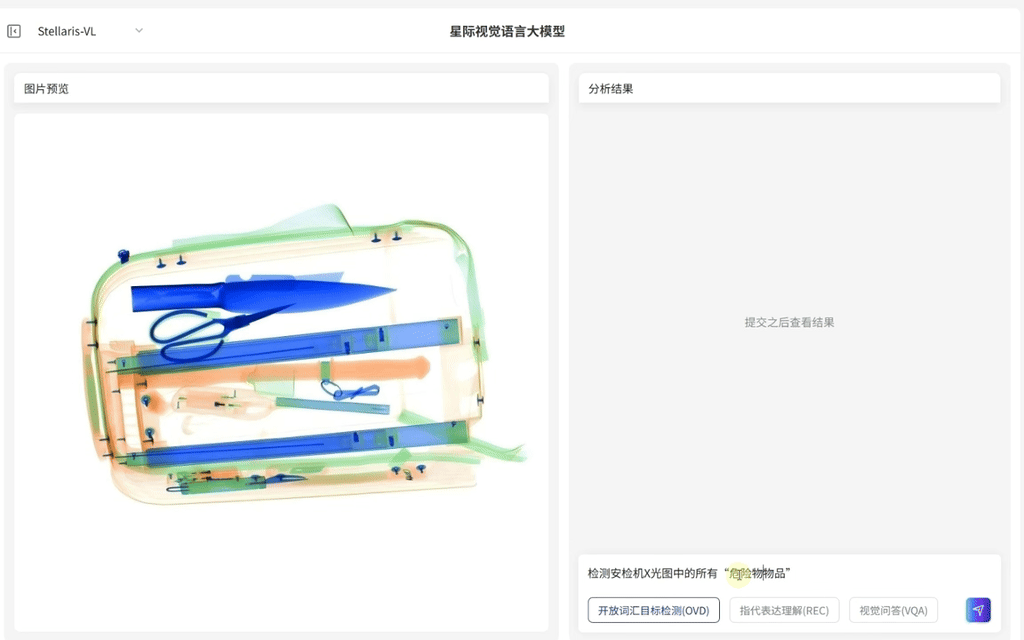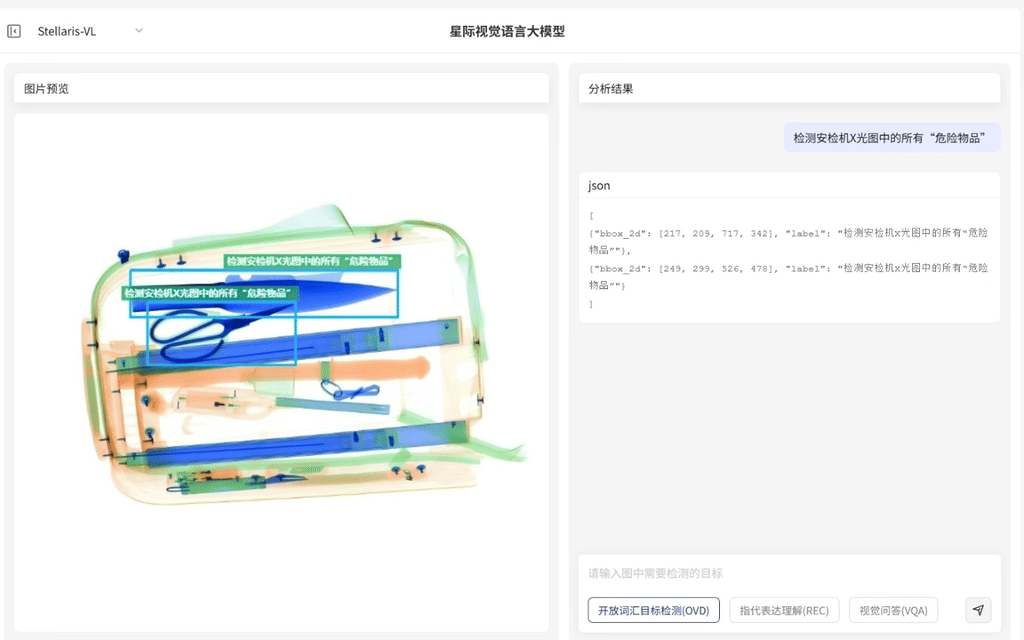
·支持输入任意词汇指令,例如车辆、垃圾、危险物品、火焰等,即可识别对应目标并输出定位框
·覆盖从生活到产业的"万物识别"需求
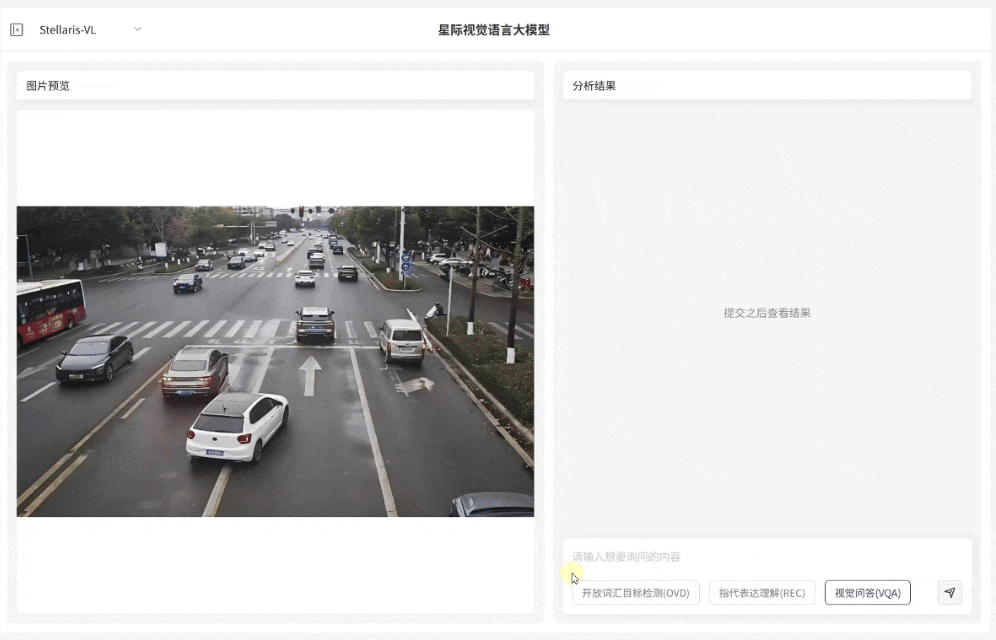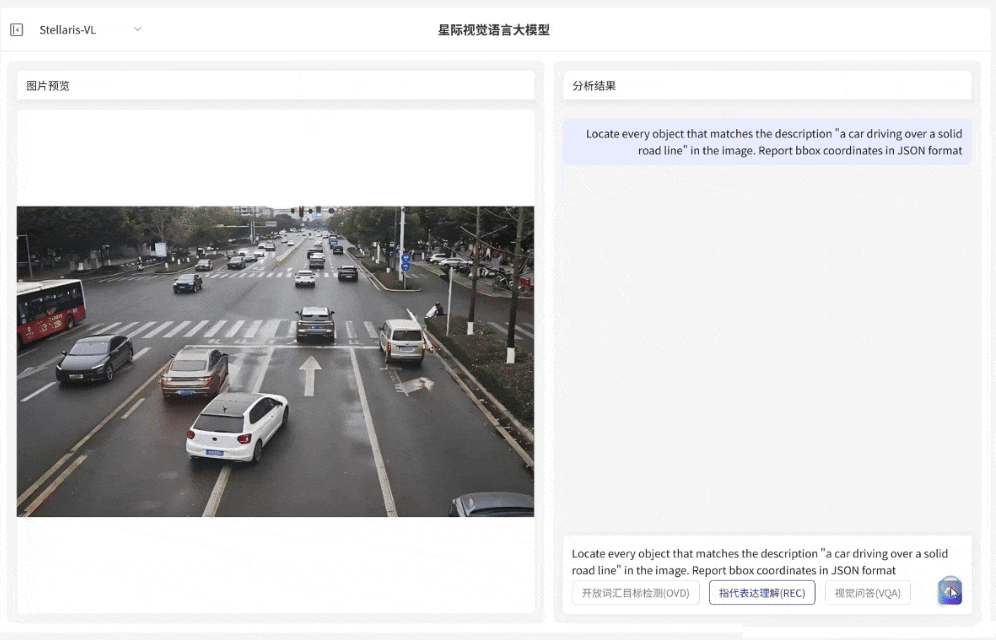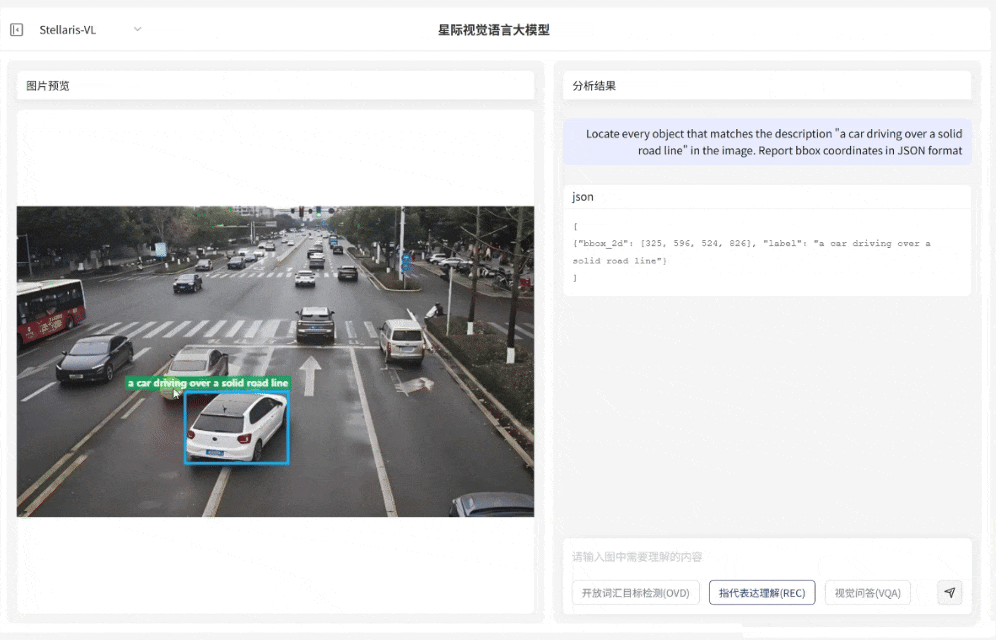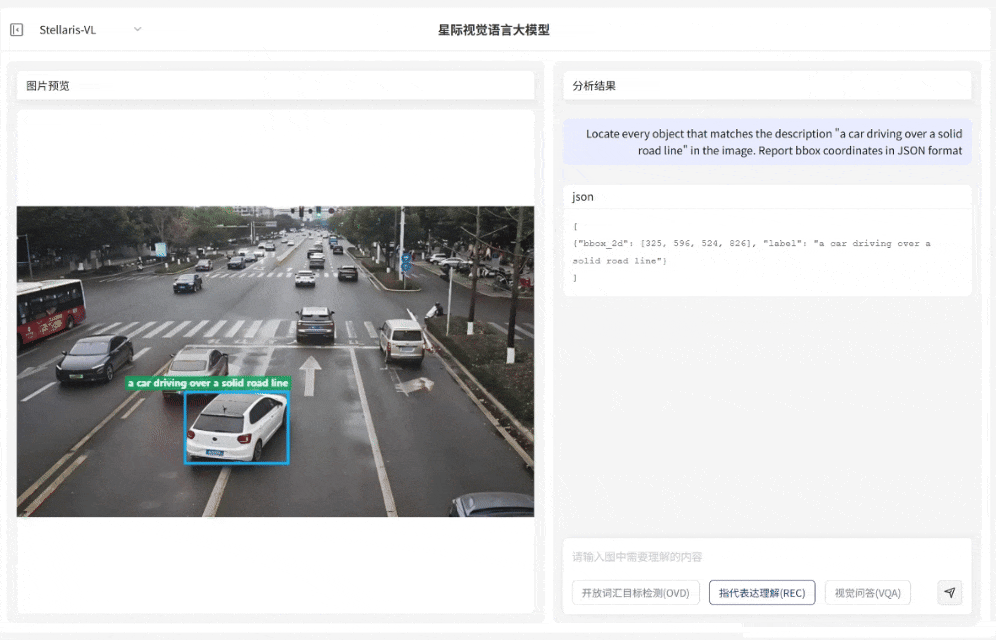
指代表达理解(REC)
定位复杂对象
·支持解析复杂自然语言指令,具备精准定位特定目标的能力
·输入短语级描述例如 “压线行驶的车辆”“河面上黄色的渔网” 等,即可快速识别对应目标并输出边界框坐标
·满足复杂场景下目标定位需求
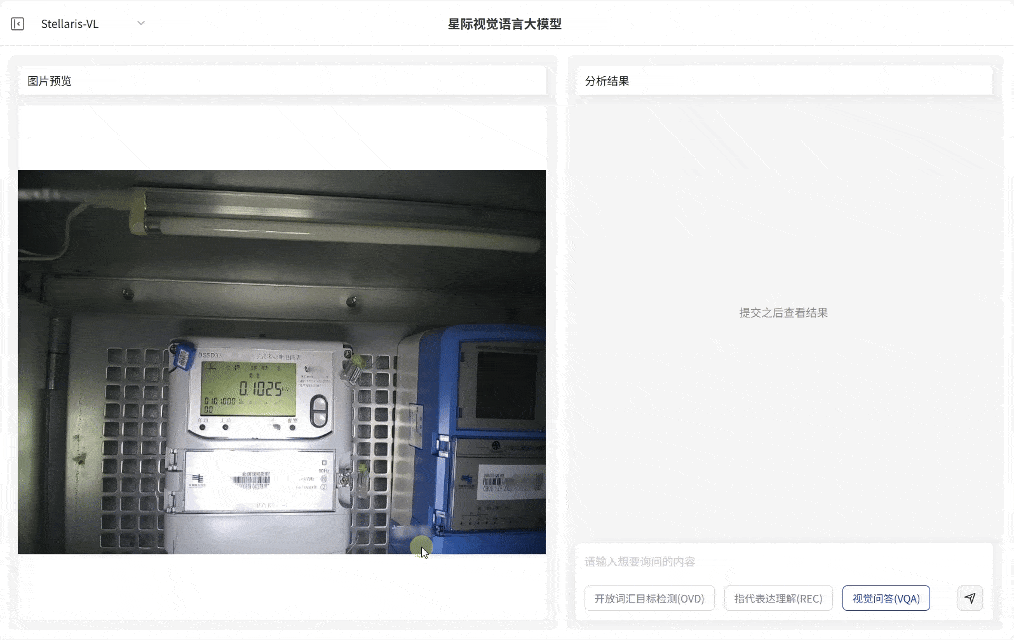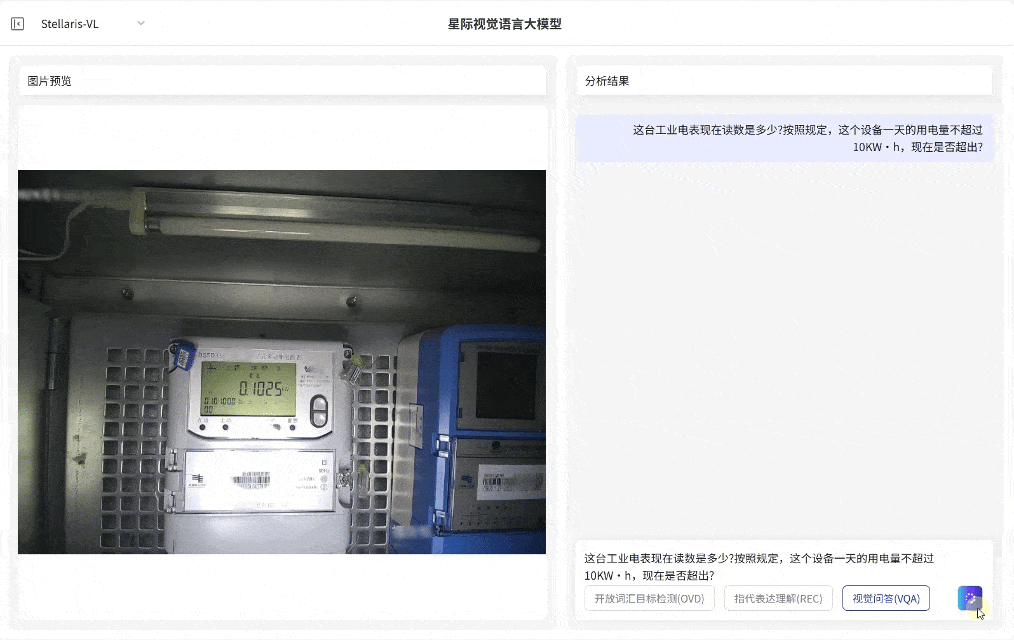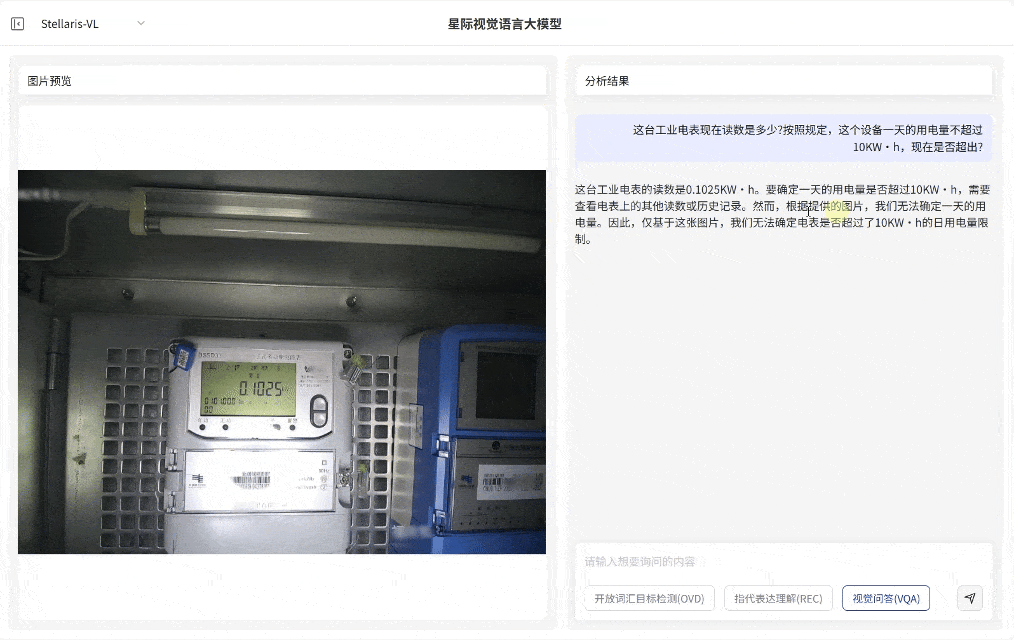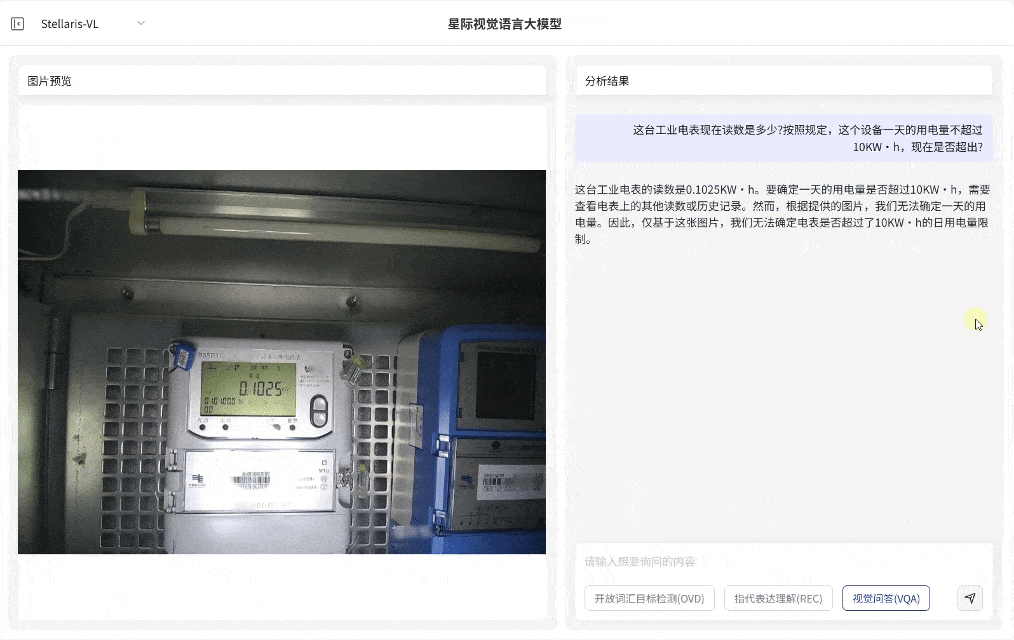
视觉问答(VQA)
场景深度分析
·无需预设问题模板,支持基于图像内容的关联问答交互,即可快速输出画面关联解读、结构化分析和推理分析
·覆盖状态研判、数量统计与关系推理等多维任务需求

OCR 与文档问答
结构化智能解析
·能直接读取图片、票据、报告等图像文本信息,解析语义内容并输出分析
图像描述
辅助业务决策
·支持将视觉信息转化为文本描述,还原场景状态和多层次信息,辅助业务场景人工复核和决策